Replacing Smokeping with Prometheus
I've been struggling with replacing parts of my old sysadmin monitoring toolkit (previously built with Nagios, Munin and Smokeping) with more modern tools (specifically Prometheus, its "exporters" and Grafana) for a while now.
Replacing Munin with Prometheus and Grafana is fairly straightforward: the network architecture ("server pulls metrics from all nodes") is similar and there are lots of exporters. They are a little harder to write than Munin modules, but that makes them more flexible and efficient, which was a huge problem in Munin. I wrote a Migrating from Munin guide that summarizes those differences. Replacing Nagios is much harder, and I still haven't quite figured out if it's worth it.
How does Smokeping work
Leaving those two aside for now, I'm left with Smokeping, which I used in my previous job to diagnose routing issues, using Smokeping as a decentralized looking glass, which was handy to debug long term issues. Smokeping is a strange animal: it's fundamentally similar to Munin, except it's harder to write plugins for it, so most people just use it for Ping, something for which it excels at.
Its trick is this: instead of doing a single ping and returning this metrics, it does multiple ones and returns multiple metrics. Specifically, smokeping will send multiple ICMP packets (20 by default), with a low interval (500ms by default) and a single retry. It also pings multiple hosts at once which means it can quickly scan multiple hosts simultaneously. You therefore see network conditions affecting one host reflected in further hosts down (or up) the chain. The multiple metrics also mean you can draw graphs with "error bars" which Smokeping shows as "smoke" (hence the name). You also get per-metric packet loss.
Basically, smokeping runs this command and collects the output in a RRD database:
fping -c $count -q -b $backoff -r $retry -4 -b $packetsize -t $timeout -i $mininterval -p $hostinterval $host [ $host ...]
... where those parameters are, by default:
$countis 20 (packets)$backoffis 1 (avoid exponential backoff)$timeoutis 1.5s$minintervalis 0.01s (minimum wait interval between any target)$hostintervalis 1.5s (minimum wait between probes on a single target)
It can also override stuff like the source address and TOS fields. This probe will complete between 30 and 60 seconds, if my math is right (0% and 100% packet loss).
How do draw Smokeping graphs in Grafana
A naive implementation of Smokeping in Prometheus/Grafana would be to use the blackbox exporter and create a dashboard displaying those metrics. I've done this at home, and then I realized that I was missing something. Here's what I did.
install the blackbox exporter:
apt install prometheus-blackbox-exportermake sure to allow capabilities so it can ping:
dpkg-reconfigure prometheus-blackbox-exporterhook monitoring targets into
prometheus.yml(the default blackbox exporter configuration is fine):scrape_configs: - job_name: blackbox metrics_path: /probe params: module: [icmp] scrape_interval: 5s static_configs: - targets: - octavia.anarc.at # hardcoded in DNS - nexthop.anarc.at - koumbit.net - dns.google relabel_configs: - source_labels: [__address__] target_label: __param_target - source_labels: [__param_target] target_label: instance - target_label: __address__ replacement: 127.0.0.1:9115 # The blackbox exporter's real hostname:port.Notice how we lower the
scrape_intervalto 5 seconds to get more samples.nexthop.anarc.atwas added into DNS to avoid hardcoding my upstream ISP's IP in my configuration.use this Grafana panel to graph the results. It was created with this query:
sum(probe_icmp_duration_seconds{phase="rtt"}) by (instance)- Set the
Legendfield to{{instance}} RTT - Set
Draw modestolinesandMode optionstostaircase - Set the
Left YaxisUnittoduration(s) - Show the
LegendAs table, withMin,Avg,MaxandCurrentenabled
Then this query, for packet loss:
1-avg_over_time(probe_success[$__interval])!=0 or null- Set the
Legendfield to{{instance}} packet loss - Set a
Add series overridetoLines: false,Null point mode: null,Points: true,Points Radius: 1,Color: deep red, and, most importantly,Y-axis: 2 - Set the
Right YaxisUnittopercent (0.0-1.0)and setY-maxto 1
Then set the entire thing to
Repeat, ontarget,vertically. And you need to add atargetvariable likelabel_values(probe_success, instance).- Set the
The result looks something like this:
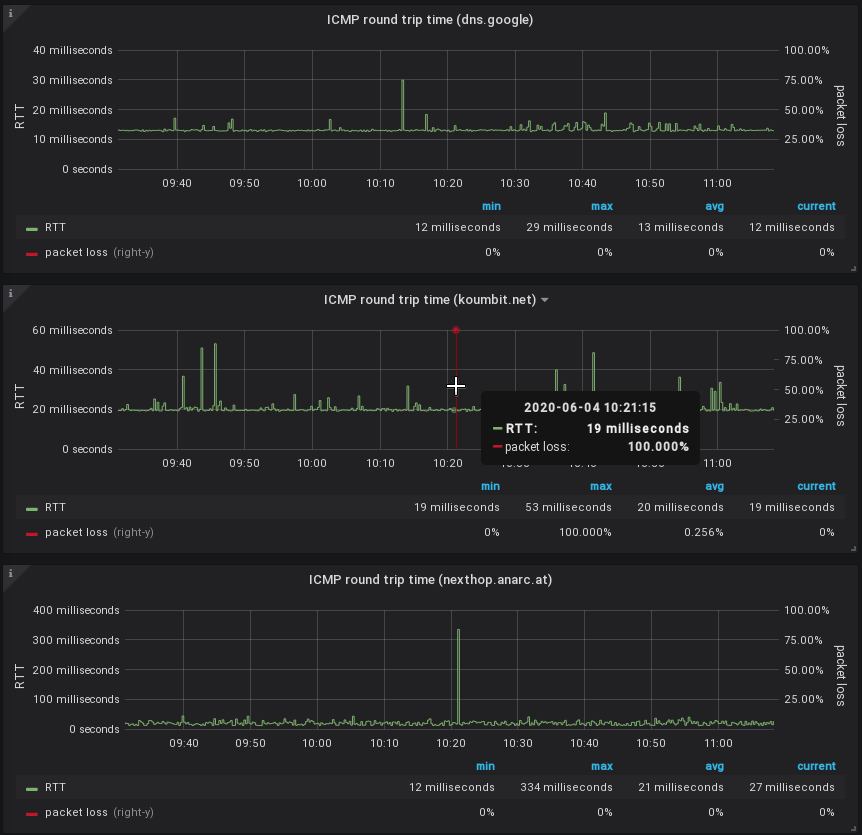
This actually looks pretty good! The resulting dashboard is available in the Grafana dashboard repository.
What is missing?
Now, that doesn't exactly look like Smokeping, does it. It's pretty good, but it's not quite what we want. What is missing is variance, the "smoke" in Smokeping.
There's a good article about replacing Smokeping with Grafana. They wrote a custom script to write samples into InfluxDB so unfortunately we can't use it in this case, since we don't have InfluxDB's query language. I couldn't quite figure out how to do the same in PromQL. I tried:
stddev(probe_icmp_duration_seconds{phase="rtt",instance=~"$instance"})
stddev_over_time(probe_icmp_duration_seconds{phase="rtt",instance=~"$instance"}[$__interval])
stddev_over_time(probe_icmp_duration_seconds{phase="rtt",instance=~"$instance"}[1m])
The first two give zero for all samples. The latter works, but doesn't look as good as Smokeping. So there might be something I'm missing.
SuperQ wrote a special exporter for this called smokeping_prober that came out of this discussion in the blackbox exporter. Instead of delegating scheduling and target definition to Prometheus, the targets are set in the exporter.
They also take a different approach than Smokeping: instead of recording the individual variations, they delegate that to Prometheus, through the use of "buckets". Then they use a query like this:
histogram_quantile(0.9 rate(smokeping_response_duration_seconds_bucket[$__interval]))
This is the rationale to SuperQ's implementation:
Yes, I know about smokeping's bursts of pings. IMO, smokeping's data model is flawed that way. This is where I intentionally deviated from the smokeping exact way of doing things. This prober sends a smooth, regular series of packets in order to be measuring at regular controlled intervals.
Instead of 20 packets, over 10 seconds, every minute. You send one packet per second and scrape every 15. This has the same overall effect, but the measurement is, IMO, more accurate, as it's a continuous stream. There's no 50 second gap of no metrics about the ICMP stream.
Also, you don't get back one metric for those 20 packets, you get several. Min, Max, Avg, StdDev. With the histogram data, you can calculate much more than just that using the raw data.
For example, IMO, avg and max are not all that useful for continuous stream monitoring. What I really want to know is the 90th percentile or 99th percentile.
This smokeping prober is not intended to be a one-to-one replacement for exactly smokeping's real implementation. But simply provide similar functionality, using the power of Prometheus and PromQL to make it better.
[...]
one of the reason I prefer the histogram datatype, is you can use the heatmap panel type in Grafana, which is superior to the individual min/max/avg/stddev metrics that come from smokeping.
Say you had two routes, one slow and one fast. And some pings are sent over one and not the other. Rather than see a wide min/max equaling a wide stddev, the heatmap would show a "line" for both routes.
That's an interesting point. I have also ended up adding a heatmap graph to my dashboard, independently. And it is true it shows those "lines" much better... So maybe that, if we ignore legacy, we're actually happy with what we get, even with the plain blackbox exporter.
So yes, we're missing pretty "fuzz" lines around the main lines, but maybe that's alright. It would be possible to do the equivalent to the InfluxDB hack, with queries like:
min_over_time(probe_icmp_duration_seconds{phase="rtt",instance=~"$instance"}[30s])
avg_over_time(probe_icmp_duration_seconds{phase="rtt",instance=~"$instance"}[5m])
max_over_time(probe_icmp_duration_seconds{phase="rtt",instance=~"$instance"}[30s])
The output looks something like this:
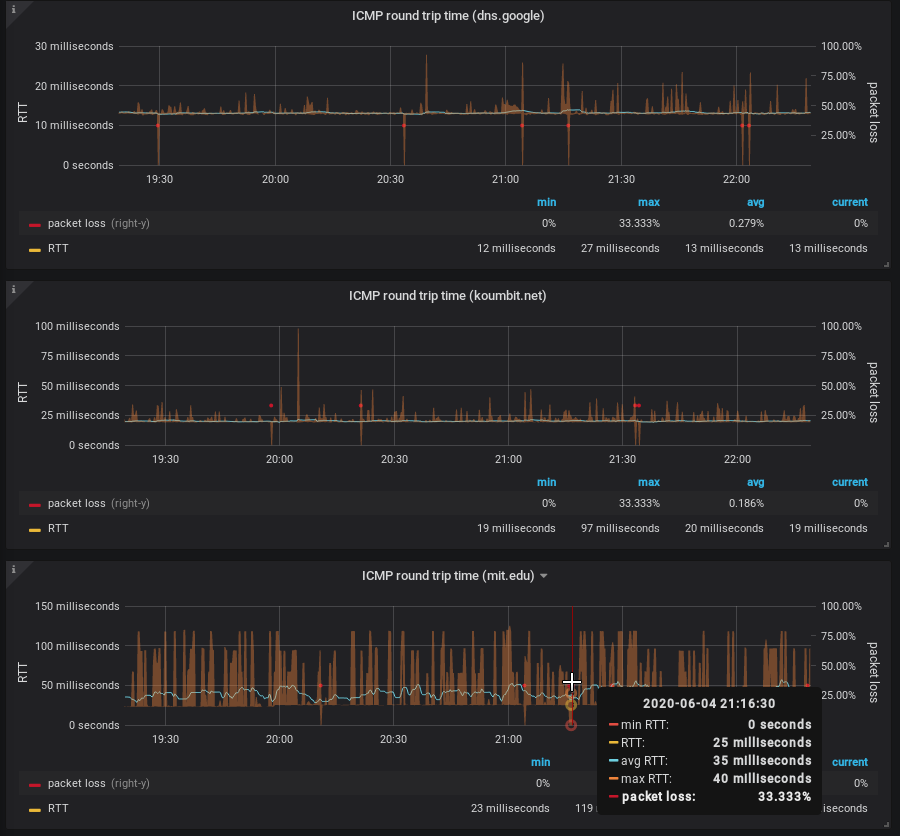
But there's a problem there: see how the middle graph "dips" sometimes
below 20ms? That's the min_over_time function (incorrectly, IMHO)
returning zero. I haven't quite figured out how to fix that, and I'm
not sure it is better. But it does look more like Smokeping than the
previous graph.
Update: I forgot to mention one big thing that this setup is missing. Smokeping has this nice feature that you can order and group probe targets in a "folder"-like hierarchy. It is often used to group probes by location, which makes it easier to scan a lot of targets. This is harder to do in this setup. It might be possible to setup location-specific "jobs" and select based on that, but it's not exactly the same.
Credits
Credits to Chris Siebenmann for his article about Prometheus and
pings which gave me the avg_over_time query idea.
Hi! This is greate article But I missing explainetion of this probes:
But I missing explainetion of this probes:
probe_icmp_duration_seconds{phase="resolve"} probe_icmp_duration_seconds{phase="rtt"} probe_icmp_duration_seconds{phase="setup"}
I don't actually know what those mean, to be honest. The blackbox exporter documentation isn't exactly exhaustive, so I can only venture a guess:
DNS (domain name resolution). I ignore this in my graphing, because it's not what I am measuring.
"RTT" stands for "Round Trip Time", this is the number "ping" gives you, the time it takes for a packet to reach its destination, for the destination to generate a new one, and for that packet to return back.
That, I frankly have no idea. I guess it's everything else the exporter might be doing to do what it needs to do? Looking at the source code it looks like it's the time it takes to setup the socket...
The dashboard is linked from the post, but in case you can't find the link, here it is again:
https://grafana.com/grafana/dashboards/12412
... unless you mean the Prometheus exporter? It's here:
https://github.com/SuperQ/smokeping_prober/
I've also added the dashboard to my personal repo in:
https://gitlab.com/anarcat/grafana-dashboards
The actual query right now in the dashboard is:
Honestly, I don't remember anymore: I fiddled with those queries for a while, but notice the
instanceparameter in the labels there, which might make thesum()part a noop, so the actual query might be better expressed as:Would love to have some more experience PromQL people fix my ugly queries.
Hi Anarcat, I wonder what solution you settled with at the end ? Do you prefer using the smokeping exporter over the blackbox one ? Which dashboard do you use finally ? Thx!
Hi Ravac!
Hum... I'm a bit confused by the question, because i thought this section was pretty clear.
I use the blackbox exporter, not the smokeping prober, as I found out about it later.
The one I uploaded to grafana.com and mentioned above.
For an even more smokeping-like graph, you can draw quantiles. Just using the regular blackbox_exporter (with 15 second scrape interval to get 20 packets per 5 mins), create 11 queries in a Grafana panel:
Set legend of these to "0", "0.1", "0.2" ... "0.9", "1". Then use series overrides with "fill down to..." rules: 1 down to 0, 0.9 down to 0.1, 0.8 down to 0.2 etc. You'll end up with something that looks a lot like smokeping!