Data rescue operations
A few general data recovery principles:
- Keep things ordered in neat little stacks: unprocessed, processing, completed, failed, incomplete, etc.
- Label everything as soon as it's identified. Use unambiguous names with incrementing unique numbers, with dates if possible.
- Do not write to the media as much as possible.
- This means you shouldn't even mount a drive that you suspect is faulty.
- Make a copy of the drive, then try to repair a copy of that copy.
Also keep in mind that Recovering data is only the first step: think about how you will archive what you restore. If it's live data, it's easier as it replaces what is already there. But if it's old data, you need to manage metadata on the medium you import. See the parent archive page for a wider discussion on the topic of archive management.
ddrescue primer
Most recovery attempts should be performed with ddrescue: it's fast for quick restores but can also go very deep with multiple retries and checks to ensure a faithful copy.
The ddrescue manual has a nice examples section detailing general principles, but a TL;DR: for disk drives is:
ddrescue -n /dev/sdb2 /srv/backup/sda2-media-20181005T135440.iso /srv/backup/sda2-media-20181005T135440.map
That does a first pass on the drive using a fast algorithm (skip areas
that have errors without retrying). If there are errors, you can do a
more thorough pass without -n but in "direct I/O" mode but otherwise
the same arguments:
ddrescue -d /dev/sdb2 /srv/backup/sda2-media-20181005T135440.iso /srv/backup/sda2-media-20181005T135440.map
The --retry-passes option (-r) can be used to specify how many
times to force ddrescue to retry that process. The examples
section has more details on those procedures. Special procedures
should be followed for CD-ROMs, detailed below.
To copy to another device you need to pass an extra --force:
ddrescue --force --no-scrape /dev/sda /dev/sdb /tmp/sda.map
And then with the scrape phase, in direct I/O mode:
ddrescue --force --idirect /dev/sda /dev/sdb /tmp/sda.map
ddrescueview
The ddrescueview utility can be read to display ddrescue log files, which may give cues as to what is going on with a drive. With automatic refresh, it might show better progress information than the commandline output.
For example, this shows ddrescue running with the --no-scrape
argument:
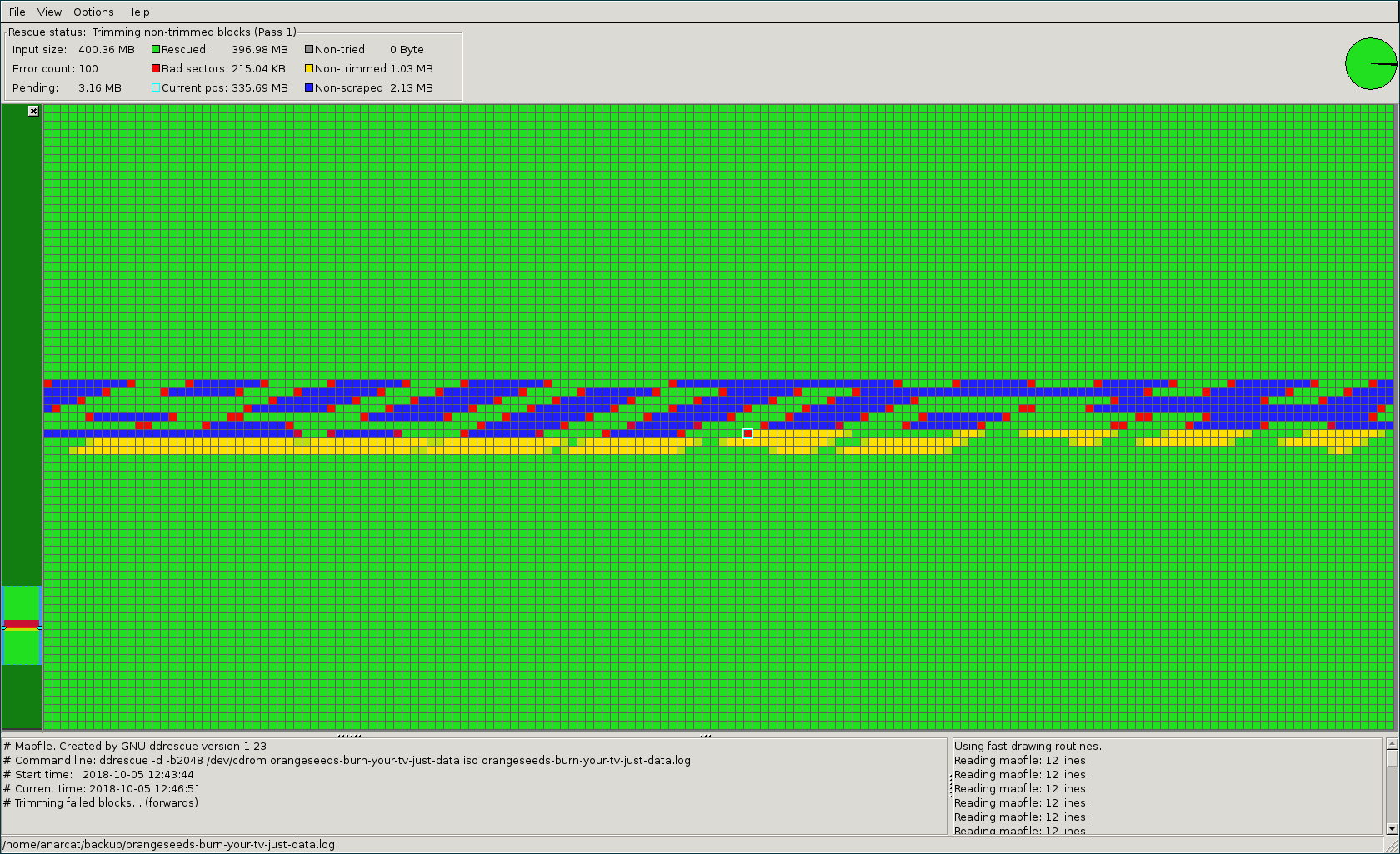
Here you see it skipped areas (in blue) that had read errors (in red). Those areas were "trimmed", that is: ddrescue tried to get as close to the error as possible to see where the faulty sectors are. In contrasts the "non-trimmed" areas (in yellow) indicate that a bulk read of that area failed but ddrescue does not know which part failed exactly.
When we rerun ddrescue without the -n argument, ddrescue will retry
the "non-scraped" area and try to restore what's inside of those
trimmed blocks as well:
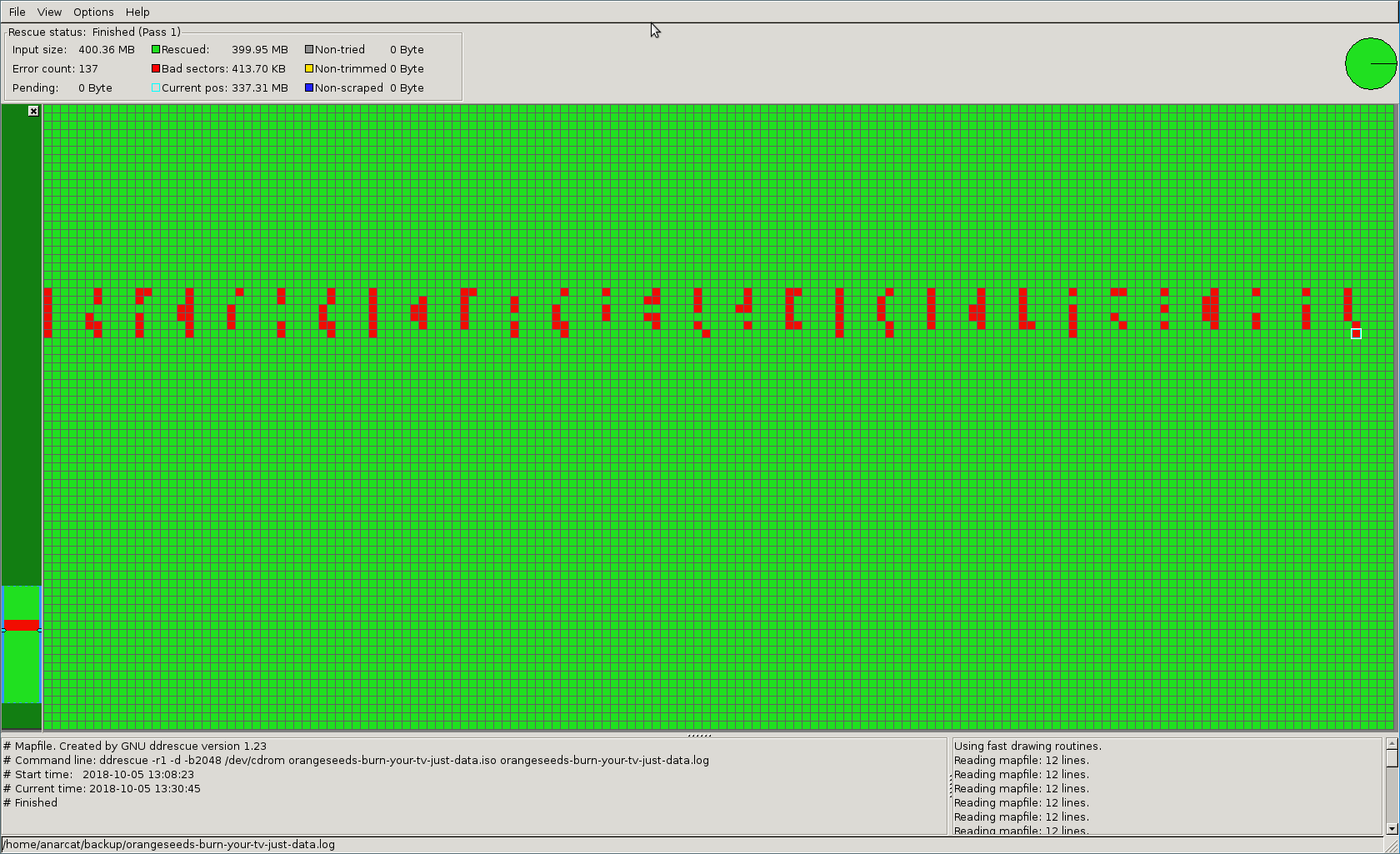
Here we see ddrescue was able to restore a lot of content, save a few sectors that were completely unreadable. Retrying again might eventually save those sectors.
Notice how both images show a typical "moire" pattern typical of rotating medium: a scratch will leave such a pattern on the data. Those results were obtained on a 16 year old CD-R disk.
Also note that jmtd wrote a tool called badiso to evaluate, based
on the ddrescue output, which files are actually recoverable.
Flash memory
Flash memory is especially tricky to recover because SSD drives and SD cards are "smart": they have an embeded controller that hides the actual storage layer. It's the same reason why it's hard to reliably destroy data on those devices as well...
I have so far used ddrescue to restore data from hard drives and flash memory is no exception.
When problems occur with flash memory, it's worth testing the card with the Fight Fake Flash (f3) program (debian package: f3). I have written documentation on those operations in the stressant manual.
CD-ROMs
Found a pile of CDs in the basement. Was looking for my old band but found much more: photos, samizdat, old backups, old games (Quake!), distro images (OpenBSD) and old windows "ghosts". Most of this is junk of course, but a few key parts of that are interesting.
Data disks
CDROMs are ripped with ddrescue:
ddrescue -n -b 2048 /dev/cdrom cdimage.iso cdimage.log
ddrescue does no retry by default, so if we're desparate and think
there's a chance to recover the rest we enable scraping (remove the
--no-scrape, -n flag) and retries (--retry-passes, -r) in
direct I/O mode (--idirect, -d):
ddrescue -d -r 3 -b 2048 /dev/cdrom cdimage.iso cdimage.log
If you are luck and have two identical copies of the same data, you
can also use the -r flag to retry an existing iso file. This is best
explained in the official manual.
Replace cdimage with the label on the disk. If there's no label,
write one! If there's already a filename with the same label,
increment.
Note that ddrescue does not support multi-session CD-ROMs. Those will
have to be ripped with cdrdao with the --session argument, see the
mixed-mode section below for examples.
Audio disks
It's unclear if (or how well) ddrescue works with audio disks. In my tests, it yields empty ISO images on audio CDs. Besides, there are other advanced techniques for those. I'm using whipper to do a faithful copy to FLAC files, using this command:
whipper cd rip --unknown --cdr
The flags are optional: --unknown allows for disks not present on
MusicBrainz and --cdr allows for copied CDs.
Mixed-mode disks
Mixed-mode disks are CD-ROMs that contain both audio and data tracks. Those are particularly challenging to archive.
Whipper will fail on mixed-mode discs, especially if the data track is at the beginning, which was the case in all the disks I have found, including the original Quake CD-ROM.
ddrescue will extract the ISO part of the disk but the kernel will
return errors for the audio part. The resulting file will be usable,
but only for the ISO part of things.
According to this article, a good way to rip those is using
cdrdao directly, for example:
cdrdao read-cd --read-raw --datafile data.bin data.toc
The problem there is that this creates only a data.bin file covering
the entire disk, and does no error correction like ddrescue does.
The files created by cdrdao then needs some post-processing to be
readable as audio or ISO. The first step is to convert the .toc file
to a .cue file:
toc2cue data.toc data.cue
If toc2cue shows this warning:
ERROR: Cannot convert: toc-file references multiple data files.
This can be corrected by forcing the same datafile to be used in all tracks of the toc file:
sed -i.orig 's/FILE "\([^"]*\)"/FILE "data.bin"/' data.toc
Then the actual data needs to be rewritten. This is done with the
bchunk package which can convert between cdrdao data files
and ISO/WAV files. As explained in this blog post, the processing
needs to be done separately between the audio and ISO parts. In the
example, the data tracks were ripped in a different session than the
audio tracks, which made it possible to use the --session argument
to extract each separately. Unfortunately, that is generally not the
case. What we're interested in, anyways, is probably more the audio
files, as the ISO file can be extracted by ddrescue. So to extract the
audio, you'll need:
data.bin data.cue data
This will convert all audio tracks to WAV files. Normally, it should
also convert ISO files, but in my experience those show up as unusable
.ugh files and the ddrescue version need to be used there. Then
the WAV files can be compressed to FLAC files using the flac
command:
flac --delete-input-file data-*.wav
This usually reduces disk usage by about 30-50% at no loss in quality. You should end up with the following files:
data-01.iso
data-02.flac
data-03.flac
data-04.flac
data-05.flac
data-06.flac
data-07.flac
data-08.flac
data-09.flac
data-10.flac
data-11.flac
data.bin
data.cue
data.map
data.toc
The .bin file is a duplicate but can be used to regenerate the
others (except the .iso file of course).
Identifying disks
cdrdao can be used to detect when the CD drive is
read. A good first command is disk-info which gives general
information about the disk but waits for the CD to be ready:
$ cdrdao disk-info
Cdrdao version 1.2.4 - (C) Andreas Mueller <andreas@daneb.de>
/dev/sr0: TSSTcorp CDDVDW TS-L633A Rev: TO01
Using driver: Generic SCSI-3/MMC - Version 2.0 (options 0x0000)
WARNING: Unit not ready, still trying...
WARNING: Unit not ready, still trying...
WARNING: Unit not ready, still trying...
That data below may not reflect the real status of the inserted medium
if a simulation run was performed before. Reload the medium in this case.
CD-RW : no
Total Capacity : n/a
CD-R medium : Prodisc Technology Inc.
Short Strategy Type, e.g. Phthalocyanine
Recording Speed : n/a
CD-R empty : no
Toc Type : CD-DA or CD-ROM
Sessions : 1
Last Track : 27
Appendable : no
The cdir command, from the cdtool package can give a
summary of the medium is present (source):
$ cdir -d /dev/cdrom
unknown cd - 40:39 in 9 tracks
16:46.13 1 [DATA]
3:46.73 2
5:34.12 3
3:05.41 4
3:06.36 5
2:02.72 6
2:13.67 7
0:34.67 8
3:26.03 9
Then the cdrdaro discid command will try to analyze the disk to compute a
CDDB disk identifier from FreeDB:
$ cdrdao discid
Cdrdao version 1.2.4 - (C) Andreas Mueller <andreas@daneb.de>
/dev/sr0: TSSTcorp CDDVDW TS-L633A Rev: TO01
Using driver: Generic SCSI-3/MMC - Version 2.0 (options 0x0000)
Track Mode Flags Start Length
------------------------------------------------------------
1 AUDIO 0 00:00:00( 0) 02:49:71( 12746)
2 AUDIO 0 02:49:71( 12746) 04:20:43( 19543)
3 AUDIO 0 07:10:39( 32289) 01:32:23( 6923)
4 AUDIO 0 08:42:62( 39212) 00:54:16( 4066)
5 AUDIO 0 09:37:03( 43278) 05:33:64( 25039)
6 AUDIO 0 15:10:67( 68317) 06:08:05( 27605)
7 AUDIO 0 21:18:72( 95922) 01:59:06( 8931)
8 AUDIO 0 23:18:03(104853) 05:07:13( 23038)
9 AUDIO 0 28:25:16(127891) 05:15:16( 23641)
10 AUDIO 0 33:40:32(151532) 04:00:38( 18038)
11 AUDIO 0 37:40:70(169570) 00:19:28( 1453)
12 AUDIO 0 38:00:23(171023) 00:06:02( 452)
13 AUDIO 0 38:06:25(171475) 00:06:02( 452)
14 AUDIO 0 38:12:27(171927) 00:06:02( 452)
15 AUDIO 0 38:18:29(172379) 00:06:02( 452)
16 AUDIO 0 38:24:31(172831) 00:06:02( 452)
17 AUDIO 0 38:30:33(173283) 00:53:52( 4027)
18 AUDIO 0 39:24:10(177310) 00:38:08( 2858)
19 AUDIO 0 40:02:18(180168) 00:46:41( 3491)
20 AUDIO 0 40:48:59(183659) 00:06:02( 452)
21 AUDIO 0 40:54:61(184111) 00:06:02( 452)
22 AUDIO 0 41:00:63(184563) 00:06:02( 452)
23 AUDIO 0 41:06:65(185015) 00:06:02( 452)
24 AUDIO 0 41:12:67(185467) 00:06:02( 452)
25 AUDIO 0 41:18:69(185919) 00:44:61( 3361)
26 AUDIO 0 42:03:55(189280) 00:38:51( 2901)
27 AUDIO 0 42:42:31(192181) 00:51:51( 3876)
Leadout AUDIO 0 43:34:07(196057)
PQ sub-channel reading (audio track) is supported, data format is BCD.
Raw P-W sub-channel reading (audio track) is supported.
Cooked R-W sub-channel reading (audio track) is supported.
Analyzing track 01 (AUDIO): start 00:00:00, length 02:49:71...
Analyzing track 02 (AUDIO): start 02:49:71, length 04:20:43...
Analyzing track 03 (AUDIO): start 07:10:39, length 01:32:23...
Analyzing track 04 (AUDIO): start 08:42:62, length 00:54:16...
Analyzing track 05 (AUDIO): start 09:37:03, length 05:33:64...
Analyzing track 06 (AUDIO): start 15:10:67, length 06:08:05...
Analyzing track 07 (AUDIO): start 21:18:72, length 01:59:06...
Analyzing track 08 (AUDIO): start 23:18:03, length 05:07:13...
Analyzing track 09 (AUDIO): start 28:25:16, length 05:15:16...
Analyzing track 10 (AUDIO): start 33:40:32, length 04:00:38...
Analyzing track 11 (AUDIO): start 37:40:70, length 00:19:28...
Analyzing track 12 (AUDIO): start 38:00:23, length 00:06:02...
Analyzing track 13 (AUDIO): start 38:06:25, length 00:06:02...
Analyzing track 14 (AUDIO): start 38:12:27, length 00:06:02...
Analyzing track 15 (AUDIO): start 38:18:29, length 00:06:02...
Analyzing track 16 (AUDIO): start 38:24:31, length 00:06:02...
Analyzing track 17 (AUDIO): start 38:30:33, length 00:53:52...
Analyzing track 18 (AUDIO): start 39:24:10, length 00:38:08...
Analyzing track 19 (AUDIO): start 40:02:18, length 00:46:41...
Analyzing track 20 (AUDIO): start 40:48:59, length 00:06:02...
Analyzing track 21 (AUDIO): start 40:54:61, length 00:06:02...
Analyzing track 22 (AUDIO): start 41:00:63, length 00:06:02...
Analyzing track 23 (AUDIO): start 41:06:65, length 00:06:02...
Analyzing track 24 (AUDIO): start 41:12:67, length 00:06:02...
Analyzing track 25 (AUDIO): start 41:18:69, length 00:44:61...
Analyzing track 26 (AUDIO): start 42:03:55, length 00:38:51...
Analyzing track 27 (AUDIO): start 42:42:31, length 00:51:51...
CDDB: Connecting to cddbp://freedb.freedb.org:888 ...
CDDB: Ok.
No CDDB record found for this toc-file.
The read-toc command will also write that data to a file. Note that
the above does not show CDTXT information, the only way to extract
that is with read-toc:
cdrdao read-toc --fast-toc tocfile
This is the command called by whipper to read the disk metadata. It
then computes a discid and a MusicBrainz hash on his own. But at this
point, all this information is shown when running whipper, so the
disk-info command is probably all we need to run here. I still run
the readtoc command to extract a TOC as sometimes that's the only
way to fetch the CDTEXT on the disk. It's also useful for archival
purposes. It will also tell us if the disk is a blank, like so:
$ cdrdao read-toc --fast-toc tocfile
Cdrdao version 1.2.4 - (C) Andreas Mueller <andreas@daneb.de>
/dev/sr0: TSSTcorp CDDVDW TS-L633A Rev: TO01
Using driver: Generic SCSI-3/MMC - Version 2.0 (options 0x0000)
WARNING: Unit not ready, still trying...
WARNING: Unit not ready, still trying...
WARNING: Unit not ready, still trying...
WARNING: Unit not ready, still trying...
ERROR: Inserted disk is empty.
To extract disk identifiers however, cdrdao is rather slow. The cd-discid command is much faster:
$ cd-discid /dev/sr0
9e0af30c 12 150 76757 87524 95692 118024 130633 141869 165637 174714 182592 184870 189598 2805
This returns the old FreeDB-style CDDB disc identifier. A more
modern version is the MusicBrainz-style checksum, which can be
read with flactag's discid command, but it's slower than
cd-diskid:
$ discid /dev/cdrom
dL5EmwESIWTPowb192SkUw5S7p4-
The above is an audio CD and will not work for data disks. And
unfortunately, just using disk-info does not suffice to identify
data CDs. For this you need the full discid run. Here's an example
of a home-made data CD:
$ cdrdao discid
Cdrdao version 1.2.4 - (C) Andreas Mueller <andreas@daneb.de>
/dev/sr0: TSSTcorp CDDVDW TS-L633A Rev: TO01
Using driver: Generic SCSI-3/MMC - Version 2.0 (options 0x0000)
Track Mode Flags Start Length
------------------------------------------------------------
1 DATA 4 00:00:00( 0) 42:53:34(193009)
Leadout DATA 4 42:53:34(193009)
PQ sub-channel reading (data track) is supported, data format is BCD.
Raw P-W sub-channel reading (data track) is supported.
Cooked R-W sub-channel reading (data track) is supported.
Analyzing track 01 (MODE1): start 00:00:00, length 42:53:34...
CDDB: Connecting to cddbp://freedb.freedb.org:888 ...
CDDB: Ok.
ERROR: CDDB: QUERY failed: 502 Already performed a query for disc ID: 00000000
ERROR: Querying of CDDB server failed.
Here the blkid command identifies ISO volumes fairly well:
$ blkid /dev/cdrom
/dev/cdrom: UUID="2008-10-22-16-06-25-00" LABEL="EntrevueDeb_fr, 22 oct 2008" TYPE="iso9660"
But it will fail on most audio CDs, except if they have a multimedia track at the beginning, which confuses things. Indeed, CDs can have different track with different medium, so it can be difficult to tell things apart. For example, here's a mixed data/audio CD ("Burn your TV", from Orange Seeds):
$ cdrdao read-toc --fast-toc tocfile
Cdrdao version 1.2.4 - (C) Andreas Mueller <andreas@daneb.de>
/dev/sr0: TSSTcorp CDDVDW TS-L633A Rev: TO01
Using driver: Generic SCSI-3/MMC - Version 2.0 (options 0x0000)
Reading toc data...
Track Mode Flags Start Length
------------------------------------------------------------
1 DATA 4 00:00:00( 0) 17:01:32( 76607)
2 AUDIO 2 17:01:32( 76607) 02:23:42( 10767)
3 AUDIO 0 19:24:74( 87374) 01:48:68( 8168)
4 AUDIO 0 21:13:67( 95542) 04:57:57( 22332)
5 AUDIO 0 26:11:49(117874) 02:48:09( 12609)
6 AUDIO 0 28:59:58(130483) 02:29:61( 11236)
7 AUDIO 0 31:29:44(141719) 05:16:68( 23768)
8 AUDIO 0 36:46:37(165487) 02:01:02( 9077)
9 AUDIO 0 38:47:39(174564) 01:45:03( 7878)
10 AUDIO 0 40:32:42(182442) 00:30:28( 2278)
11 AUDIO 0 41:02:70(184720) 01:03:03( 4728)
12 AUDIO 0 42:05:73(189448) 04:37:69( 20844)
Leadout AUDIO 0 46:43:67(210292)
PQ sub-channel reading (data track) is supported, data format is BCD.
Raw P-W sub-channel reading (data track) is supported.
Cooked R-W sub-channel reading (data track) is supported.
PQ sub-channel reading (audio track) is supported, data format is BCD.
Raw P-W sub-channel reading (audio track) is supported.
Cooked R-W sub-channel reading (audio track) is supported.
Analyzing track 01 (MODE1): start 00:00:00, length 16:59:32...
Analyzing track 02 (AUDIO): start 17:01:32, length 02:23:42...
Found pre-gap: 00:02:00
Analyzing track 03 (AUDIO): start 19:24:74, length 01:48:68...
Analyzing track 04 (AUDIO): start 21:13:67, length 04:57:57...
Analyzing track 05 (AUDIO): start 26:11:49, length 02:48:09...
Analyzing track 06 (AUDIO): start 28:59:58, length 02:29:61...
Analyzing track 07 (AUDIO): start 31:29:44, length 05:16:68...
Analyzing track 08 (AUDIO): start 36:46:37, length 02:01:02...
Analyzing track 09 (AUDIO): start 38:47:39, length 01:45:03...
Analyzing track 10 (AUDIO): start 40:32:42, length 00:30:28...
Analyzing track 11 (AUDIO): start 41:02:70, length 01:03:03...
Analyzing track 12 (AUDIO): start 42:05:73, length 04:37:69...
Reading of toc data finished successfully.
Notice the first track is a DATA track (MODE1 later). Extracting
this disk will require first running ddrescue on the first track and
whipper on the rest. We'll see how it goes...
The isoinfo command, part of the genisoimage package,
can provide extended information on data disks. For example, here's
the information available in the "Burn Your TV" multimedia disk:
$ isoinfo -d -i /dev/sr0
CD-ROM is in ISO 9660 format
System id: FreeBSD
Volume id: Burn Your TV Multimedia
Volume set id:
Publisher id:
Data preparer id:
Application id: MKISOFS ISO 9660/HFS FILESYSTEM BUILDER & CDRECORD CD-R/DVD CREATOR (C) 1993 E.YOUNGDALE (C) 1997 J.PEARSON/J.SCHILLING
Copyright File id:
Abstract File id:
Bibliographic File id:
Volume set size is: 1
Volume set sequence number is: 1
Logical block size is: 2048
Volume size is: 76352
Joliet with UCS level 3 found
Rock Ridge signatures version 1 found
Remaining work
All the archives created were dumped in the ~/archive or ~/mp3
directories on curie. Data needs to be deduplicated,
replicated, and archived somewhere more logical.
Inventory
I have a bunch of piles:
- a spindle of disks that consists mostly of TV episodes, movies, distro and Windows images/ghosts. not imported.
- a pile of tapes and Zip drives. not imported.
- about fourty backup disks. not imported.
- about five "books" disks of various sorts. ISOs generated. partly integrated in my collection, others failed to import or were in formats that were considered non-recoverable
- a bunch of orange seeds piles
- Burn Your TV masters and copies
- apparently live and unique samples - mostly imported in
mp3 - really old stuff with tons of dupes - partly sorted through, in
jams4, reste still in the pile
- a pile of unidentified disks
all disks were eventually identified as trash, blanks, perfect, finished, defective, or not processed. A special needs attention stack was the "to do" pile, and would get sorted through the other piles. each pile was labeled with a sticky note and taped together summarily.
this page was printed and attached included in the box, along with a post-it linking to the blog post announcing the work for posterity.
here is a summary of what's in the box.
| Type | Count | Note |
|---|---|---|
| trash | 13 | non-recoverable. not detected by the Linux kernel at all and no further attempt has been made to recover them. |
| blanks | 3 | never written to, still usable |
| perfect | 28 | successfully archived, without errors |
| finished | 4 | almost perfect: but mixed-mode or multi-session |
| defective | 21 | found to have errors but not considered important enough to re-process |
| total | 69 | |
| not processed | ~100 | visual estimate |
Note that this might be poor storage on my part, others have had more luck with their CDs, see this report from a fellow Debian developer for example:
for all explicitly selected media - TDK, JVC and Verbatim - they hold for 10-20 years
There are other similar reports:
Surprisingly, with no special storage precautions, generic low-cost media, and consumer drives, I'm getting good data from CD-Rs more than 20 years old, and from DVD-Rs nearly 18 years old.
That said, many of the disks processed here might have crossed the 10-20 year threshold: the archival work was done in 2018, and it's unclear how old the disks were. Some were certainly older than at least 2004 (so 14 years old), others likely much older (previous millennia).
References
I'm following the path blazed by jmtd here and here. (Update: inspired by this very post, jmtd collected his notes in a new page.) The forensics wiki also has docs on ddrescue which were useful.
Tools used:
Other tools:
- wodim's readom is supposedly better to rip "optical media" (hence OM) but in this post it says it's not as good as ddrescue to deal with damaged medium
- isovfy: to check ISO images, TBD. the source seems to say it does not really check anything and so wrote a different tool...
- ... called isolyzer: check if the recorded size of an ISO file matches the actual size