Updates in container isolation
This article is part of a series on KubeCon Europe 2018.
- Diversity, education, privilege and ethics in technology
- Autoscaling for Kubernetes workloads
- Updates in container isolation (this article)
- Securing the container image supply chain
- Easier container security with entitlements
KubeCon EU At KubeCon + CloudNativeCon Europe 2018, several talks explored the topic of container isolation and security. The last year saw the release of Kata Containers which, combined with the CRI-O project, provided strong isolation guarantees for containers using a hypervisor. During the conference, Google released its own hypervisor called gVisor, adding yet another possible solution for this problem. Those new developments prompted the community to work on integrating the concept of "secure containers" (or "sandboxed containers") deeper into Kubernetes. This work is now coming to fruition; it prompts us to look again at how Kubernetes tries to keep the bad guys from wreaking havoc once they break into a container.
Attacking and defending the container boundaries

Tim Allclair's talk (slides [PDF], video) was all about explaining the possible attacks on secure containers. To simplify, Allclair said that "secure is isolation, even if that's a little imprecise" and explained that isolation is directional across boundaries: for example, a host might be isolated from a guest container, but the container might be fully visible from the host. So there are two distinct problems here: threats from the outside (attackers trying to get into a container) and threats from the inside (attackers trying to get out of a compromised container). Allclair's talk focused on the latter. In this context, sandboxed containers are concerned with threats from the inside; once the attacker is inside the sandbox, they should not be able to compromise the system any further.
Attacks can take multiple forms: untrusted code provided by users in multi-tenant clusters, un-audited code fetched from random sites by trusted users, or trusted code compromised through an unknown vulnerability. According to Allclair, defending a system from a compromised container is harder than defending a container from external threats, because there is a larger attack surface. While outside attackers only have access to a single port, attackers on the inside often have access to the kernel's extensive system-call interface, a multitude of storage backends, the internal network, daemons providing services to the cluster, hardware interfaces, and so on.
Taking those vectors one by one, Allclair first looked at the kernel and said that there were 169 code execution vulnerabilities in the Linux kernel in 2017. He admitted this was a bit of fear mongering; it indeed was a rather unusual year and "most of those were in mobile device drivers". These vulnerabilities are not really a problem for Kubernetes unless you run it on your phone. Allclair said that at least one attendee at the conference was probably doing exactly that; as it turns out, some people have managed to run Kubernetes on a vacuum cleaner. Container runtimes implement all sorts of mechanisms to reduce the kernel's attack surface: Docker has seccomp profiles, but Kubernetes turns those off by default. Runtimes will use AppArmor or SELinux rule sets. There are also ways to run containers as non-root, which was the topic of a pun-filled separate talk as well. Unfortunately, those mechanisms do not fundamentally solve the problem of kernel vulnerabilities. Allclair cited the Dirty COW vulnerability as a classic example of a container escape through race conditions on system calls that are allowed by security profiles.
The proposed solution to this problem is to add a second security boundary. This is apparently an overarching principle at Google, according to Allclair: "At Google, we have this principle security principle that between any untrusted code and user data there have to be at least two distinct security boundaries so that means two independent security mechanisms need to fail in order to for that untrusted code to get out that user data."
Adding another boundary makes attacks harder to accomplish. One such
solution is to use a hypervisor like Kata Containers or gVisor. Those
new runtimes depend on a sandboxed setting that is still in the
proposal stage in the Kubernetes API.
gVisor as an extra boundary

Let's look at gVisor as an example hypervisor. Google spent five years developing the project in the dark before sharing it with the world. At KubeCon, it was introduced in a keynote and a more in-depth talk (slides [PDF], video) by Dawn Chen and Zhengyu He. gVisor is a user-space kernel that implements a subset of the Linux kernel API, but which was written from scratch in Go. The idea is to have an independent kernel that reduces the attack surface; while the Linux kernel has 20 million lines of code, at the time of writing gVisor only has 185,000, which should make it easier to review and audit. It provides a cleaner and simpler interface: no hardware drivers, interrupts, or I/O port support to implement, as the host operating system takes care of all that mess.
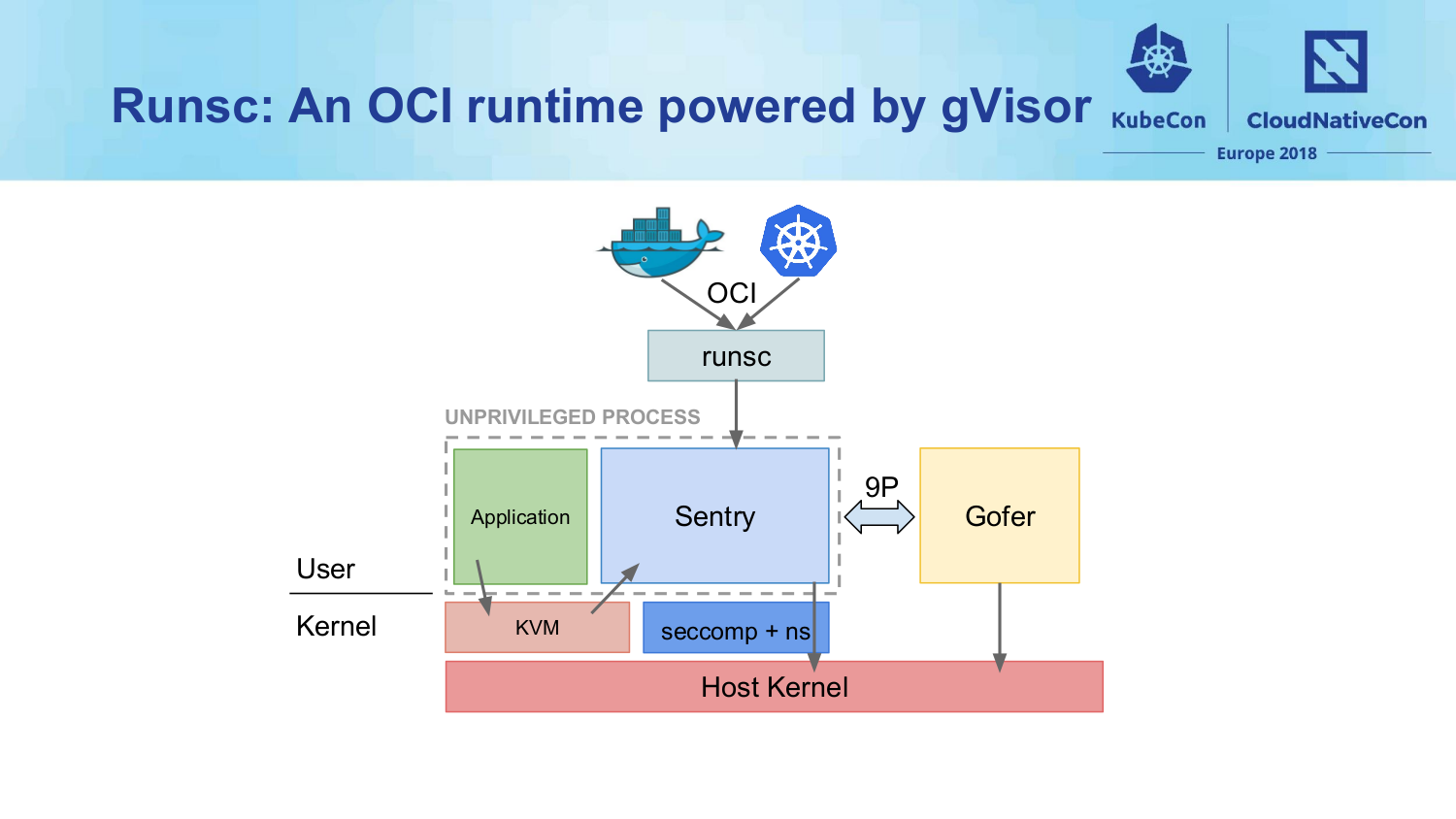
As we can see in the diagram above (taken from the talk slides),
gVisor has a component called "sentry" that implements the core of the
system-call logic. It uses ptrace() out of the box for portability
reasons, but can also work with KVM for better security and performance,
as ptrace() is slow and racy. Sentry can use KVM to map processes to
CPUs and provide lower-level support like privilege separation and
memory-management. He suggested thinking of gVisor as a "layered
solution" to provide isolation, as it also uses seccomp filters and
namespaces. He explained how it differed from user-mode Linux (UML):
while UML is a port of Linux to user space, gVisor actually reimplements
the Linux system calls (211 of the 319 x86-64 system calls) using only
64 system calls in the host system. Another key difference from other
systems, like unikernels or Google's Native
Client (NaCL), is that it
can run unmodified binaries. To fix classes of attacks relying on the
open() system call, gVisor also forbids any direct filesystem access;
all filesystem operations go through a second process called the
gopher that enforces access permissions, in another example of a
double security boundary.

According to He, gVisor has a 150ms startup time and 15MB overhead,
close to Kata Containers startup times, but smaller in terms of
memory. He said the approach is good for small containers in
high-density workloads. It is not so useful for trusted images
(because it's not required), workloads that make heavy use of system
calls (because of the performance overhead), or workloads that require
hardware access (because that's not available at all). Even though
gVisor implements a large number of system calls, some functionality is
missing. There is no System V shared memory, for example, which means
PostgreSQL does not work
under gVisor. A simple ping might not work either, as gVisor lacks
SOCK_RAW support. Linux
has been in use for decades now and is more than just a set of system
calls: interfaces like /proc and sysfs also make Linux what it is.
gVisor implements none of those Of those, gVisor only implements a
subset of /proc currently, with the result that some containers will
not work with gVisor without modification, for now.
As an aside, the new hypervisor does allow for experimentation and development of new system calls directly in user space. The speakers confirmed this was another motivation for the project; the hope is that having a user-space kernel will allow faster iteration than working directly in the Linux kernel.
Escape from the hypervisor
Of course, hypervisors like gVisor are only a part of the solution to pod security. In his talk, Allclair warned that even with a hypervisor, there are still ways to escape a container. He cited the CVE-2017-1002101 vulnerability, which allows hostile container images to take over a host through specially crafted symbolic links. Like native containers, hypervisors like Kata Containers also allow the guest to mount filesystems across the container boundary, so they are vulnerable to such an attack.
Kubernetes fixed that specific bug, but a general solution is still in the design phase. Allclair said that ephemeral storage should be treated as opaque to the host, making sure that the host never interacts directly with image files and just passes them down to the guest untouched. Similarly, runtimes should "mount block volumes directly into the sandbox, not onto the host". Network filesystems are trickier; while it's possible to mount (say) a Ceph filesystem in the guest, that means the access credentials now reside within the guest, which moves the security boundary into the untrusted container.
Allclair outlined networking as another attack vector: Kubernetes exposes a lot of unauthenticated services on the network by default. In particular, the API server is a gold mine of information about the cluster. Another attack vector is untrusted data flows from containers to the user. For example, container logs travel through various Kubernetes components, and some components, like Fluentd, will end up parsing those logs directly. Allclair said that many different programs are "looking at untrusted data; if there's a vulnerability there, it could lead to remote code execution". When he looked at the history of vulnerabilities in that area, he could find no direct code execution, but "one of the dependencies in Fluentd for parsing JSON has seven different bugs with segfault issues so we can see that could lead to a memory vulnerability". As a possible solution to such issues, Allclair proposed isolating components in their own (native, as opposed to sandboxed) containers, which might be sufficient because Fluentd acts as a first trusted boundary.
Conclusion
A lot of work is happening to improve what is widely perceived as defective container isolation in the Linux kernel. Some take the approach of trying to run containers as regular users ("root-less containers") and rely on the Linux kernel's user-isolation properties. Others found this relies too much on the security of the kernel and use separate hypervisors, like Kata Containers and gVisor. The latter seems especially interesting because it is lightweight and doesn't add much attack surface. In comparison, Kata Containers relies on a kernel running inside the container, which actually expands the attack surface instead of reducing it. The proposed API for sandboxed containers is currently experimental in the containerd and CRI-O projects; Allclair expects the API to ship in alpha as part the Kubernetes 1.12 release.
It's important to keep in mind that hypervisors are not a panacea: they do not support all workloads because of compatibility and performance issues. A hypervisor is only a partial solution; Allclair said the next step is to provide hardened interfaces for storage, logging, and networking and encouraged people to get involved in the node special interest group and the proposal [Google Docs] on the topic.
This article first appeared in the Linux Weekly News.