The cost of hosting in the cloud
This is one part of my coverage of KubeCon Austin 2017. Other articles include:
- An overview of KubeCon + CloudNativeCon
- Docker without Docker at Red Hat
- Demystifying Container Runtimes
- Monitoring with Prometheus 2.0
- Changes in Prometheus 2.0
- The cost of hosting in the cloud (this article)
Should we host in the cloud or on our own servers? This question was at the center of Dmytro Dyachuk's talk, given during KubeCon + CloudNativeCon last November. While many services simply launch in the cloud without the organizations behind them considering other options, large content-hosting services have actually moved back to their own data centers: Dropbox migrated in 2016 and Instagram in 2014. Because such transitions can be expensive and risky, understanding the economics of hosting is a critical part of launching a new service. Actual hosting costs are often misunderstood, or secret, so it is sometimes difficult to get the numbers right. In this article, we'll use Dyachuk's talk to try to answer the "million dollar question": "buy or rent?"
Computing the cost of compute
So how much does hosting cost these days? To answer that apparently trivial question, Dyachuk presented a detailed analysis made from a spreadsheet that compares the costs of "colocation" (running your own hardware in somebody else's data center) versus those of hosting in the cloud. For the latter, Dyachuk chose Amazon Web Services (AWS) as a standard, reminding the audience that "63% of Kubernetes deployments actually run off AWS". Dyachuk focused only on the cloud and colocation services, discarding the option of building your own data center as too complex and expensive. The question is whether it still makes sense to operate your own servers when, as Dyachuk explained, "CPU and memory have become a utility", a transition that Kubernetes is also helping push forward.
Another assumption of his talk is that server uptime isn't that critical anymore; there used to be a time when system administrators would proudly brandish multi-year uptime counters as a proof of server stability. As an example, Dyachuk performed a quick survey in the room and the record was an uptime of 5 years. In response, Dyachuk asked: "how many security patches were missed because of that uptime?" The answer was, of course "all of them". Kubernetes helps with security upgrades, in that it provides a self-healing mechanism to automatically re-provision failed services or rotate nodes when rebooting. This changes hardware designs; instead of building custom, application-specific machines, system administrators now deploy large, general-purpose servers that use virtualization technologies to host arbitrary applications in high-density clusters.
When presenting his calculations, Dyachuk explained that "pricing is complicated" and, indeed, his spreadsheet includes hundreds of parameters. However, after reviewing his numbers, I can say that the list is impressively exhaustive, covering server memory, disk, and bandwidth, but also backups, storage, staffing, and networking infrastructure.
For servers, he picked a Supermicro chassis with 224 cores and 512GB of memory from the first result of a Google search. Once amortized over an aggressive three-year rotation plan, the $25,000 machine ends up costing about $8,300 yearly. To compare with Amazon, he picked the m4.10xlarge instance as a commonly used standard, which currently offers 40 cores, 160GB of RAM, and 4Gbps of dedicated storage bandwidth. At the time he did his estimates, the going rate for such a server was $2 per hour or $17,000 per year. So, at first, the physical server looks like a much better deal: half the price and close to quadruple the capacity. But, of course, we also need to factor in networking, power usage, space rental, and staff costs. And this is where things get complicated.
First, colocation rates will vary a lot depending on location. While bandwidth costs are often much lower in large urban centers because of proximity to fast network links, real estate and power prices are often much higher. Bandwidth costs are now the main driver in hosting costs.
For the purpose of his calculation, Dyachuk picked a real-estate figure of $500 per standard cabinet (42U). His calculations yielded a monthly power cost of $4,200 for a full rack, at $0.50/kWh. Those rates seem rather high for my local data center, where that rate is closer to $350 for the cabinet and $0.12/kWh for power. Dyachuk took into account that power is usually not "metered billing", when you pay for the actual power usage, but "stepped billing" where you pay for a circuit with a (say) 25-amp breaker regardless of how much power you use in said circuit. This accounts for some of the discrepancy, but the estimate still seems rather too high to be accurate according to my calculations.
Then there's networking: all those machines need to connect to each other and to an uplink. This means finding a bandwidth provider, which Dyachuk pinned at a reasonable average cost of $1/Mbps. But the most expensive part is not the bandwidth; the cost of managing network infrastructure includes not only installing switches and connecting them, but also tracing misplaced wires, dealing with denial-of-service attacks, and so on. Cabling, a seemingly innocuous task, is actually the majority of hardware expenses in data centers, as previously reported. From networking, Dyachuk went on to detail the remaining cost estimates, including storage and backups, where the physical world is again cheaper than the cloud. All this is, of course, assuming that crafty system administrators can figure out how to glue all the hardware together into a meaningful package.
Which brings us to the sensitive question of staff costs; Dyachuk described those as "substantial". These costs are for the system and network administrators who are needed to buy, order, test, configure, and deploy everything. Evaluating those costs is subjective: for example, salaries will vary between different countries. He fixed the person yearly salary costs at $250,000 (counting overhead and an actual $150,000 salary) and accounted for three people on staff. Those costs may also vary with the colocation service; some will include remote hands and networking, but he assumed in his calculations that the costs would end up being roughly the same because providers will charge extra for those services.
Dyachuk also observed that staff costs are the majority of the expenses in a colocation environment: "hardware is cheaper, but requires a lot more people". In the cloud, it's the opposite; most of the costs consist of computation, storage, and bandwidth. Staff also introduce a human factor of instability in the equation: in a small team, there can be a lot of variability in ability levels. This means there is more uncertainty in colocation cost estimates.
In our discussions after the conference, Dyachuk pointed out a social aspect to consider: cloud providers are operating a virtual oligopoly. Dyachuk worries about the impact of Amazon's growing power over different markets:
A lot of businesses are in direct competition with Amazon. A fear of losing commercial secrets and being spied upon has not been confirmed by any incidents yet. But Walmart, for example, moved out of AWS and requested that its suppliers do the same.
Demand management
Once the extra costs described are factored in, colocation still would appear to be the cheaper option. But that doesn't take into account the question of capacity: a key feature of cloud providers is that they pool together large clusters of machines, which allow individual tenants to scale up their services quickly in response to demand spikes. Self-hosted servers need extra capacity to cover for future demand. That means paying for hardware that stays idle waiting for usage spikes, while cloud providers are free to re-provision those resources elsewhere.
Satisfying demand in the cloud is easy: allocate new instances automatically and pay the bill at the end of the month. In a colocation, provisioning is much slower and hardware must be systematically over-provisioned. Those extra resources might be used for preemptible batch jobs in certain cases, but workloads are often "transaction-oriented" or "realtime" which require extra resources to deal with spikes. So the "spike to average" ratio is an important metric to evaluate when making the decision between the cloud and colocation.
Cost reductions are possible by improving analytics to reduce over-provisioning. Kubernetes makes it easier to estimate demand; before containerized applications, estimates were per application, each with its margin of error. By pooling together all applications in a cluster, the problem is generalized and individual workloads balance out in aggregate, even if they fluctuate individually. Therefore Dyachuk recommends to use the cloud when future growth cannot be forecast, to avoid the risk of under-provisioning. He also recommended "The Art of Capacity Planning" as a good forecasting resource; even though the book is old, the basic math hasn't changed so it is still useful.
The golden ratio
Colocation prices finally overshoot cloud prices after adding extra capacity and staff costs. In closing, Dyachuk identified the crossover point where colocation becomes cheaper at around $100,000 per month, or 150 Amazon m4.2xlarge instances, which can be seen in the graph below. Note that he picked a different instance type for the actual calculations: instead of the largest instance (m4.10xlarge), he chose the more commonly used m4.2xlarge instance. Because Amazon pricing scales linearly, the math works out to about the same once reserved instances, storage, load balancing, and other costs are taken into account.
He also added that the figure will change based on the workload; Amazon is more attractive with more CPU and less I/O. Inversely, I/O-heavy deployments can be a problem on Amazon; disk and network bandwidth are much more expensive in the cloud. For example, bandwidth can sometimes be more than triple what you can easily find in a data center.
Your mileage may vary; those numbers shouldn't be taken as an absolute. They are a baseline that needs to be tweaked according to your situation, workload and requirements. For some, Amazon will be cheaper, for others, colocation is still the best option.
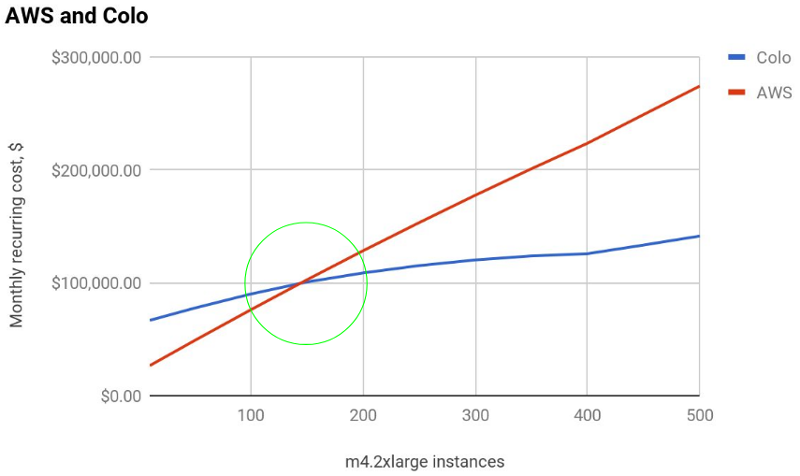
He also emphasized that the graph stops at 500 instances; beyond that lies another "wall" of investment due to networking constraints. At around the equivalent of 2000-3000 Amazon instances, networking becomes a significant bottleneck and demands larger investments in networking equipment to upgrade internal bandwidth, which may make Amazon affordable again. It might also be that application design should shift to a multi-cluster setup, but that implies increases in staff costs.
Finally, we should note that some organizations simply cannot host in the cloud. In our discussions, Dyachuk specifically expressed concerns about Canada's government services moving to the cloud, for example: what is the impact on state sovereignty when confidential data about its citizen ends up in the hands of private contractors? So far, Canada's approach has been to only move "public data" to the cloud, but Dyachuk pointed out this already includes sensitive departments like correctional services.
In Dyachuk's model, the cloud offers significant cost reduction over traditional hosting in small clusters, at least until a deployment reaches a certain size. However, different workloads significantly change that model and can make colocation attractive again: I/O and bandwidth intensive services with well-planned growth rates are clear colocation candidates. His model is just a start; any project manager would be wise to make their own calculations to confirm the cloud really delivers the cost savings it promises. Furthermore, while Dyachuk wisely avoided political discussions surrounding the impact of hosting in the cloud, data ownership and sovereignty remain important considerations that shouldn't be overlooked.
A YouTube video and the slides [PDF] from Dyachuk's talk are available online.
This article first appeared in the Linux Weekly News, under the title "The true costs of hosting in the cloud".